CNN网络实践 引入包 1 2 3 4 5 6 7 8 import torch.nn as nnimport torch.nn.functional as Fimport numpy as npimport torchfrom torch.utils.data import Datasetimport pandas as pd%matplotlib inline
读入数据集 onehot编码
iloc()函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 targetDict = { 109 : torch.Tensor([1 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 ]), 122 : torch.Tensor([0 , 1 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 ]), 135 : torch.Tensor([0 , 0 , 1 , 0 , 0 , 0 , 0 , 0 , 0 , 0 ]), 174 : torch.Tensor([0 , 0 , 0 , 1 , 0 , 0 , 0 , 0 , 0 , 0 ]), 189 : torch.Tensor([0 , 0 , 0 , 0 , 1 , 0 , 0 , 0 , 0 , 0 ]), 201 : torch.Tensor([0 , 0 , 0 , 0 , 0 , 1 , 0 , 0 , 0 , 0 ]), 213 : torch.Tensor([0 , 0 , 0 , 0 , 0 , 0 , 1 , 0 , 0 , 0 ]), 226 : torch.Tensor([0 , 0 , 0 , 0 , 0 , 0 , 0 , 1 , 0 , 0 ]), 238 : torch.Tensor([0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 1 , 0 ]), 97 : torch.Tensor([0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 1 ]) } output2lable = [torch.Tensor([1 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 ]), torch.Tensor([0 , 1 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 ]), torch.Tensor([0 , 0 , 1 , 0 , 0 , 0 , 0 , 0 , 0 , 0 ]), torch.Tensor([0 , 0 , 0 , 1 , 0 , 0 , 0 , 0 , 0 , 0 ]), torch.Tensor([0 , 0 , 0 , 0 , 1 , 0 , 0 , 0 , 0 , 0 ]), torch.Tensor([0 , 0 , 0 , 0 , 0 , 1 , 0 , 0 , 0 , 0 ]), torch.Tensor([0 , 0 , 0 , 0 , 0 , 0 , 1 , 0 , 0 , 0 ]), torch.Tensor([0 , 0 , 0 , 0 , 0 , 0 , 0 , 1 , 0 , 0 ]), torch.Tensor([0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 1 , 0 ]), torch.Tensor([0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 1 ])] print (targetDict[109 ])class bearDataset (Dataset ): """ 数据集演示 """ def __init__ (self, csv_file, dim ): self.dim = dim self.df = pd.read_csv(csv_file) def __len__ (self ): return len (self.df) def __getitem__ (self, idx ): x = torch.tensor( self.df.iloc[idx, 0 :self.dim].values, dtype=torch.float ) x = x.view(1 , 400 ) y = self.df.iloc[idx, 2000 ] y = targetDict[y] return [x, y]
tensor([1., 0., 0., 0., 0., 0., 0., 0., 0., 0.])
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 ds_demo = bearDataset( 'C:/Users/JINTIAN/Desktop/代码/PytorchCode/项目数据集/train.csv' , 400 ) dl = torch.utils.data.DataLoader( ds_demo, batch_size=1000 , shuffle=True , num_workers=0 ) x1, y1 = ds_demo.__getitem__(11 ) print (x1) print (x1.shape)print (y1) idata = iter (dl) x, y = next (idata) print (x)print (x.shape)print (y)print (y.shape)
tensor([[ 0.1037, 0.0555, -0.0096, -0.0547, -0.0682, -0.0524, -0.0179, 0.0238,
0.0661, 0.0935, 0.0918, 0.0409, -0.0225, -0.0880, -0.1535, -0.1640,
-0.1462, -0.0985, -0.0415, -0.0083, 0.0273, 0.0409, 0.0382, 0.0054,
-0.0501, -0.0887, -0.1039, -0.0801, -0.0440, -0.0108, 0.0221, 0.0478,
0.0822, 0.1081, 0.0855, 0.0257, -0.0321, -0.0657, -0.0611, -0.0365,
-0.0177, 0.0048, 0.0332, 0.0684, 0.0951, 0.0903, 0.0463, -0.0211,
-0.0734, -0.0895, -0.0724, -0.0401, -0.0040, 0.0463, 0.0989, 0.1277,
0.1362, 0.1066, 0.0250, -0.0663, -0.1204, -0.1287, -0.0947, -0.0465,
-0.0038, 0.0509, 0.0989, 0.1500, 0.1663, 0.1122, 0.0467, -0.0198,
-0.0565, -0.0590, -0.0482, -0.0350, -0.0244, 0.0083, 0.0446, 0.0732,
0.0565, 0.0046, -0.0486, -0.0862, -0.0665, -0.0342, 0.0002, 0.0323,
0.0515, 0.0968, 0.1145, 0.0912, 0.0515, -0.0131, -0.0434, -0.0467,
-0.0334, 0.0104, 0.0365, 0.0676, 0.0953, 0.1364, 0.1775, 0.1512,
0.0962, 0.0169, -0.0463, -0.0680, -0.0793, -0.0597, -0.0271, 0.0136,
0.0643, 0.0928, 0.0962, 0.0607, 0.0006, -0.0359, -0.0415, -0.0238,
-0.0044, 0.0021, 0.0323, 0.0634, 0.0882, 0.1147, 0.0935, 0.0647,
0.0344, 0.0188, 0.0265, 0.0117, 0.0042, -0.0017, 0.0192, 0.0640,
0.0859, 0.0910, 0.0732, 0.0478, 0.0417, 0.0419, 0.0411, 0.0317,
0.0119, 0.0119, 0.0311, 0.0668, 0.0718, 0.0446, 0.0169, -0.0148,
-0.0154, -0.0169, -0.0165, -0.0125, -0.0008, 0.0509, 0.0933, 0.1318,
0.1400, 0.1026, 0.0630, 0.0342, 0.0323, 0.0213, 0.0044, 0.0021,
0.0225, 0.0584, 0.0857, 0.0966, 0.0695, 0.0321, 0.0094, 0.0119,
0.0250, 0.0204, 0.0179, 0.0390, 0.0774, 0.1187, 0.1381, 0.1145,
0.0638, -0.0031, -0.0365, -0.0307, -0.0238, -0.0052, 0.0136, 0.0613,
0.1254, 0.1519, 0.1490, 0.1099, 0.0522, 0.0271, 0.0213, 0.0029,
-0.0211, -0.0457, -0.0570, -0.0338, 0.0067, 0.0190, -0.0038, -0.0492,
-0.0878, -0.1104, -0.1279, -0.1406, -0.1510, -0.1406, -0.1168, -0.0559,
-0.0077, -0.0255, -0.0839, -0.1636, -0.1807, -0.1823, -0.1802, -0.1356,
-0.1137, -0.0780, -0.0478, -0.0192, -0.0021, -0.0570, -0.0980, -0.1204,
-0.1043, -0.0398, -0.0167, -0.0131, -0.0146, -0.0013, 0.0302, 0.0388,
0.0227, -0.0255, -0.0524, -0.0469, -0.0273, -0.0058, -0.0148, -0.0184,
-0.0104, 0.0244, 0.0695, 0.0862, 0.0899, 0.0613, 0.0492, 0.0726,
0.0682, 0.0584, 0.0403, 0.0355, 0.0749, 0.1233, 0.1594, 0.1212,
0.0584, 0.0407, 0.0494, 0.0784, 0.0993, 0.1118, 0.1064, 0.1043,
0.1172, 0.1181, 0.0991, 0.0688, 0.0524, 0.0513, 0.0668, 0.0776,
0.0505, -0.0002, -0.0273, -0.0150, 0.0255, 0.0611, 0.0609, 0.0355,
0.0240, 0.0365, 0.0401, 0.0338, -0.0163, -0.0757, -0.0816, -0.0513,
0.0058, 0.0409, 0.0478, 0.0330, 0.0202, 0.0267, 0.0046, -0.0426,
-0.0941, -0.1218, -0.1024, -0.0576, -0.0211, -0.0152, -0.0240, -0.0184,
-0.0038, 0.0050, -0.0259, -0.0953, -0.1602, -0.1844, -0.1462, -0.1020,
-0.0720, -0.0471, -0.0188, 0.0332, 0.0736, 0.0755, 0.0067, -0.0897,
-0.1396, -0.1375, -0.0895, -0.0421, -0.0071, 0.0060, 0.0081, 0.0302,
0.0252, -0.0063, -0.0653, -0.1141, -0.1089, -0.0741, -0.0073, 0.0369,
0.0515, 0.0640, 0.0722, 0.0859, 0.0471, -0.0319, -0.1164, -0.1748,
-0.1467, -0.0870, -0.0113, 0.0478, 0.0786, 0.1218, 0.1323, 0.1256,
0.0657, -0.0305, -0.0885, -0.1185, -0.0755, -0.0156, 0.0371, 0.0907,
0.1133, 0.1556, 0.1792, 0.1675, 0.1118, 0.0211, -0.0350, -0.0553,
-0.0229, 0.0181, 0.0294, 0.0486, 0.0826, 0.1285, 0.1287, 0.0832,
0.0363, -0.0113, -0.0096, 0.0357, 0.0962, 0.1425, 0.1508, 0.1658,
0.1727, 0.1621, 0.1273, 0.0713, 0.0288, -0.0054, 0.0021, 0.0309]])
torch.Size([1, 400])
tensor([1., 0., 0., 0., 0., 0., 0., 0., 0., 0.])
tensor([[[-0.3764, -0.6076, -0.8242, ..., 0.2153, 0.3919, 0.5388]],
[[ 0.2809, 0.4340, 0.5613, ..., -0.3155, -0.4678, -0.5692]],
[[-1.0104, -0.8004, -0.4507, ..., 0.5763, 0.4357, 0.2191]],
...,
[[-0.0013, -0.0332, -0.0559, ..., -0.1903, -0.0924, 0.0196]],
[[ 0.0785, 0.0317, 0.0797, ..., -0.1131, -0.2045, -0.1916]],
[[-0.0096, -0.0338, -0.0355, ..., -0.1273, -0.1494, -0.1273]]])
torch.Size([1000, 1, 400])
tensor([[1., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 1., 0., 0.],
[0., 0., 1., ..., 0., 0., 0.],
...,
[0., 1., 0., ..., 0., 0., 0.],
[1., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 1., 0., 0.]])
torch.Size([1000, 10])
构建网络 Conv1d()和Conv2d()区别
conv1d详细用法
如何计算卷积网络的尺寸(公式)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 class Net (nn.Module): def __init__ (self ): super (Net, self).__init__() self.conv1 = nn.Conv1d(1 , 64 , kernel_size=11 , stride=4 ) self.pool1 = nn.MaxPool1d(3 , stride=2 ) self.conv2 = nn.Conv1d(64 , 128 , kernel_size=3 ) self.pool2 = nn.MaxPool1d(3 , stride=2 ) self.fc1 = nn.Linear(22 *128 , 22 *64 ) self.fc2 = nn.Linear(22 *64 , 500 ) self.fc3 = nn.Linear(500 , 10 ) def forward (self, x ): x = self.pool1(F.relu(self.conv1(x))) x = self.pool2(F.relu(self.conv2(x))) x = x.view(-1 , 22 *128 ) x = F.relu(self.fc1(x)) x = F.relu(self.fc2(x)) x = self.fc3(x) return x net = Net() print (net)
Net(
(conv1): Conv1d(1, 64, kernel_size=(11,), stride=(4,))
(pool1): MaxPool1d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv2): Conv1d(64, 128, kernel_size=(3,), stride=(1,))
(pool2): MaxPool1d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
(fc1): Linear(in_features=2816, out_features=1408, bias=True)
(fc2): Linear(in_features=1408, out_features=500, bias=True)
(fc3): Linear(in_features=500, out_features=10, bias=True)
)
1 2 3 4 5 import torch.optim as optimcriterion = nn.CrossEntropyLoss() optimizer = optim.Adam(net.parameters())
开始训练 enumerate()函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 loss_list = [] x_list = [] for epoch in range (100 ): running_loss = 0.0 for i, data in enumerate (dl, 0 ): inputs, labels = data optimizer.zero_grad() outputs = net(inputs) loss = nn.CrossEntropyLoss() res = loss(outputs, labels) res.backward() optimizer.step() running_loss += res.item() if i % 20 == 0 : print ('[%d, %5d] loss: %.5f' % (epoch + 1 , i, running_loss / 20 )) loss_list.append(running_loss / 20 ) x_list.append(epoch*100 +i) running_loss = 0.0 print ('Finished Training' )
[1, 0] loss: 0.11560
[2, 0] loss: 0.10816
[3, 0] loss: 0.10406
[4, 0] loss: 0.10030
[5, 0] loss: 0.09376
[6, 0] loss: 0.08903
[7, 0] loss: 0.08112
[8, 0] loss: 0.07515
[9, 0] loss: 0.06976
[10, 0] loss: 0.06235
[11, 0] loss: 0.06183
[12, 0] loss: 0.05548
[13, 0] loss: 0.05526
[14, 0] loss: 0.04942
[15, 0] loss: 0.04974
[16, 0] loss: 0.04542
[17, 0] loss: 0.04663
[18, 0] loss: 0.04146
[19, 0] loss: 0.04268
[20, 0] loss: 0.04244
[21, 0] loss: 0.03886
[22, 0] loss: 0.04085
[23, 0] loss: 0.03681
[24, 0] loss: 0.03655
[25, 0] loss: 0.03605
[26, 0] loss: 0.03463
[27, 0] loss: 0.03309
[28, 0] loss: 0.03342
[29, 0] loss: 0.03143
[30, 0] loss: 0.03075
[31, 0] loss: 0.02923
[32, 0] loss: 0.02879
[33, 0] loss: 0.02753
[34, 0] loss: 0.02645
[35, 0] loss: 0.02521
[36, 0] loss: 0.02453
[37, 0] loss: 0.02356
[38, 0] loss: 0.02244
[39, 0] loss: 0.02177
[40, 0] loss: 0.02063
[41, 0] loss: 0.01998
[42, 0] loss: 0.01928
[43, 0] loss: 0.01841
[44, 0] loss: 0.01762
[45, 0] loss: 0.01702
[46, 0] loss: 0.01625
[47, 0] loss: 0.01556
[48, 0] loss: 0.01509
[49, 0] loss: 0.01438
[50, 0] loss: 0.01373
[51, 0] loss: 0.01312
[52, 0] loss: 0.01256
[53, 0] loss: 0.01212
[54, 0] loss: 0.01175
[55, 0] loss: 0.01171
[56, 0] loss: 0.01280
[57, 0] loss: 0.01157
[58, 0] loss: 0.01030
[59, 0] loss: 0.00939
[60, 0] loss: 0.01008
[61, 0] loss: 0.01057
[62, 0] loss: 0.00840
[63, 0] loss: 0.00928
[64, 0] loss: 0.01041
[65, 0] loss: 0.00745
[66, 0] loss: 0.01025
[67, 0] loss: 0.01061
[68, 0] loss: 0.00787
[69, 0] loss: 0.01133
[70, 0] loss: 0.00717
[71, 0] loss: 0.00910
[72, 0] loss: 0.00646
[73, 0] loss: 0.00830
[74, 0] loss: 0.00706
[75, 0] loss: 0.00806
[76, 0] loss: 0.00628
[77, 0] loss: 0.00786
[78, 0] loss: 0.00644
[79, 0] loss: 0.01000
[80, 0] loss: 0.00878
[81, 0] loss: 0.01111
[82, 0] loss: 0.00684
[83, 0] loss: 0.01090
[84, 0] loss: 0.00600
[85, 0] loss: 0.00747
[86, 0] loss: 0.00538
[87, 0] loss: 0.00774
[88, 0] loss: 0.00504
[89, 0] loss: 0.00619
[90, 0] loss: 0.00443
[91, 0] loss: 0.00461
[92, 0] loss: 0.00471
[93, 0] loss: 0.00392
[94, 0] loss: 0.00499
[95, 0] loss: 0.00378
[96, 0] loss: 0.00412
[97, 0] loss: 0.00401
[98, 0] loss: 0.00354
[99, 0] loss: 0.00373
[100, 0] loss: 0.00302
Finished Training
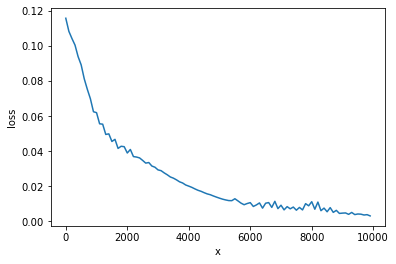
1 2 3 4 5 6 import matplotlib.pyplot as pltplt.plot(x_list, loss_list) plt.xlabel('x' ) plt.ylabel('loss' ) plt.show()
开始测试 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 ds_test = bearDataset( 'C:/Users/JINTIAN/Desktop/代码/PytorchCode/项目数据集/test.csv' , 400 ) dl_test = torch.utils.data.DataLoader( ds_test, batch_size=1 , shuffle=True , num_workers=0 ) correct = 0 total = 0 with torch.no_grad(): for data, lable in dl_test: outputs = net(data) _, predicted = torch.max (outputs.data, 1 ) p = output2lable[predicted.item()] total += lable.size(0 ) if (p.equal(lable[0 ])): correct = correct+1 print ('total is ' , total)print ('Accuracy of the network: %d %%' % ( 100 * correct / total))
total is 300
Accuracy of the network: 93 %