多层感知机MLP
引子
之前的回归模型已经能解决一些线性模型,但是对于非线性问题,用之前的去模拟是不合适的,我们需要在神经网络中加入隐藏层,形成非线性模型,实现对模型预测的普适性
从零开始实现MLP
一些准备工作:引入包,加载数据集
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| from d2l import torch as d2l
from torch.utils import data
from torchvision import transforms
from torch import nn
import torchvision
import torch
d2l.use_svg_display()
def load_data_fashion_mnist(batch_size, resize=None):
"""下载Fashion-MNIST数据集,然后将其加载到内存中"""
trans = [transforms.ToTensor()]
if resize:
trans.insert(0, transforms.Resize(resize))
trans = transforms.Compose(trans)
mnist_train = torchvision.datasets.FashionMNIST(
root="./data", train=True, transform=trans, download=True)
mnist_test = torchvision.datasets.FashionMNIST(
root="./data", train=False, transform=trans, download=True)
return (data.DataLoader(mnist_train, batch_size, shuffle=True,
num_workers=get_dataloader_workers()),
data.DataLoader(mnist_test, batch_size, shuffle=False,
num_workers=get_dataloader_workers()))
def get_dataloader_workers():
return 4
|
1
2
3
| batch_size = 256
train_iter, test_iter = load_data_fashion_mnist(batch_size)
|
将每个图像视为具有784个输入特征 和10个类的简单分类数据集。 首先,我们将实现一个具有单隐藏层的多层感知机, 它包含256个隐藏单元
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| num_inputs, num_outputs, num_hiddens = 784, 10, 256
W1 = nn.Parameter(torch.randn(
num_inputs, num_hiddens, requires_grad=True)*0.01)
b1 = nn.Parameter(torch.zeros(num_hiddens, requires_grad=True))
W2 = nn.Parameter(torch.randn(
num_hiddens, num_outputs, requires_grad=True)*0.01)
b2 = nn.Parameter(torch.zeros(num_outputs, requires_grad=True))
params = [W1, b1, W2, b2]
|
增加非线性,隐藏层使用激活函数
1
2
3
4
|
def relu(X):
a=torch.zeros_like(X)
return torch.max(X,a)
|
1
2
3
4
5
6
| def net(X):
X = X.reshape((-1, num_inputs))
H = relu(X@W1+b1)
return (H@W2+b2)
|
损失函数
1
2
| loss = nn.CrossEntropyLoss(reduction='none')
|
1
2
3
4
5
6
| num_epochs, lr = 10, 0.1
updater = torch.optim.SGD(params, lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, updater)
|
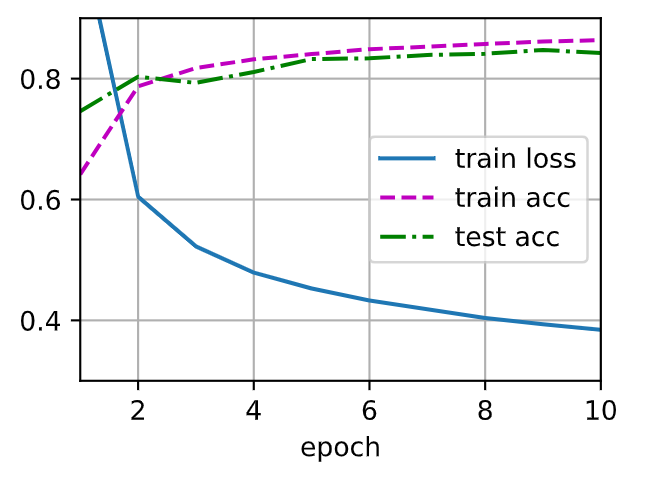
1
| d2l.predict_ch3(net,test_iter,n=10)
|

pytorch框架实现MLP
1
2
3
4
5
6
| from d2l import torch as d2l
from torch.utils import data
from torchvision import transforms
from torch import nn
import torchvision
import torch
|
我们添加了2个全连接层,第一层是隐藏层,它包含256个隐藏单元,并使用了ReLU激活函数。 第二层是输出层。
1
2
3
4
5
6
7
8
9
10
11
12
13
| net = nn.Sequential(nn.Flatten(),
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 10))
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights)
|
Sequential(
(0): Flatten(start_dim=1, end_dim=-1)
(1): Linear(in_features=784, out_features=256, bias=True)
(2): ReLU()
(3): Linear(in_features=256, out_features=10, bias=True)
)
训练!
1
2
3
4
5
6
7
8
9
| batch_size = 256
lr = 0.1
num_epochs = 10
loss = nn.CrossEntropyLoss(reduction='none')
trainer = torch.optim.SGD(net.parameters(), lr=lr)
train_iter, test_iter = load_data_fashion_mnist(batch_size)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
|
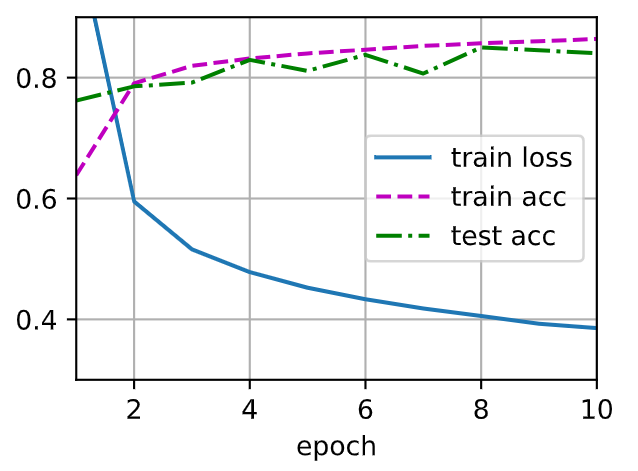
1
2
| d2l.predict_ch3(net, test_iter)
|
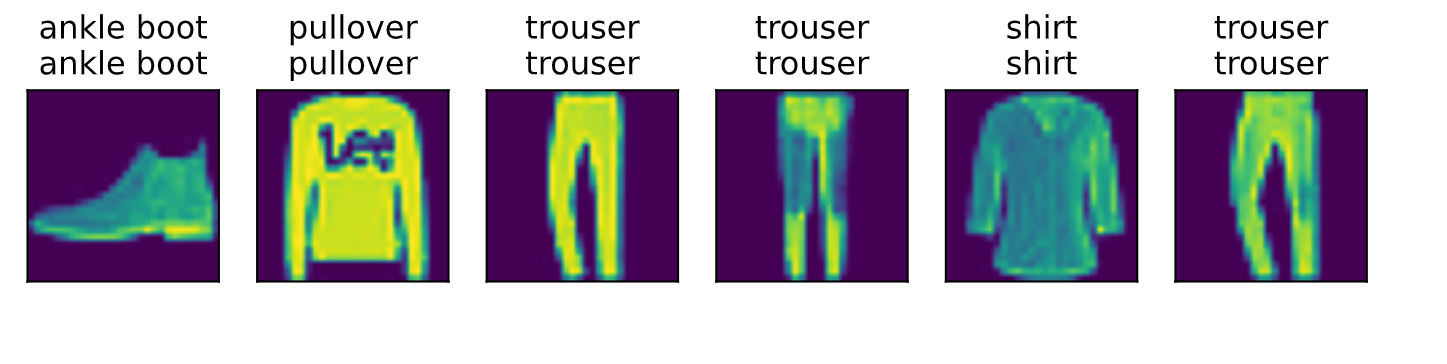
学了MLP感觉思路清晰了很多,之前看封装好的代码框架如同看天书,现在总算找到一点规律了,总算有点进展了热泪盈眶
今晚得以安眠








